| 1. Базы данных и СУБД | ||||||
| 2. Инфологическая модель данных "Сущность-связь" |
|
|||||
| 3. Реляционный подход | ||||||
| 4. Введение в проектирование реляционных баз данных | ||||||
| 5. Об языке SQL | ||||||
| 6. Запросы с использованием единственной таблицы | ||||||
| 7. Запросы с использованием нескольких таблиц | ||||||
| 8. Предложения модификации данных SQL | ||||||
| 9. О предложениях определения данных и оптимизации запросов | ||||||
| 10. Пример проектирования базы данных | ||||||
| Литература | ||||||
| Приложения | ||||||
| О проекте | ||||||
1.1. Данные и ЭВМВосприятие реального мира можно соотнести с последовательностью разных, хотя иногда и взаимосвязанных, явлений. С давних времен люди пытались описать эти явления (даже тогда, когда не могли их понять). Такое описание называют данными. Традиционно фиксация данных осуществляется с помощью конкретного средства общения (например, с помощью естественного языка или изображений) на конкретном носителе (например, камне или бумаге). Обычно данные (факты, явления, события, идеи или предметы) и их интерпретация (семантика) фиксируются совместно, так как естественный язык достаточно гибок для представления того и другого. Примером может служить утверждение "Стоимость авиабилета 128". Здесь "128" – данное, а "Стоимость авиабилета" – его семантика. Нередко данные и интерпретация разделены. Например, "Расписание движения самолетов" может быть представлено в виде таблицы (рис. 1.1), в верхней части которой (отдельно от данных) приводится их интерпретация. Такое разделение затрудняет работу с данными (попробуйте быстро получить сведения из нижней части таблицы). Применение ЭВМ для ведения и обработки данных обычно приводит к еще большему разделению данных и интерпретации. ЭВМ имеет дело главным образом с данными как таковыми. Большая часть интерпретирующей информации вообще не фиксируется в явной форме (ЭВМ не "знает", является ли "21.50" стоимостью авиабилета или временем вылета). Почему же это произошло? Существует по крайней мере две исторические причины, по которым применение ЭВМ привело к отделению данных от интерпретации. Во-первых, ЭВМ не обладали достаточными возможностями для обработки текстов на естественном языке – основном языке интерпретации данных. Во-вторых, стоимость памяти ЭВМ была первоначально весьма велика. Память использовалась для хранения самих данных, а интерпретация традиционно возлагалась на пользователя. Пользователь закладывал интерпретацию данных в свою программу, которая "знала", например, что шестое вводимое значение связано с временем прибытия самолета, а четвертое – с временем его вылета. Это существенно повышало роль программы, так как вне интерпретации данные представляют собой не более чем совокупность битов на запоминающем устройстве. Жесткая зависимость между данными и использующими их программами создает серьезные проблемы в ведении данных и делает использования их менее гибкими. Нередки случаи, когда пользователи одной и той же ЭВМ создают и используют в своих программах разные наборы данных, содержащие сходную информацию. Иногда это связано с тем, что пользователь не знает (либо не захотел узнать), что в соседней комнате или за соседним столом сидит сотрудник, который уже давно ввел в ЭВМ нужные данные. Чаще потому, что при совместном использовании одних и тех же данных возникает масса проблем. Разработчики прикладных программ (написанных, например, на Бейсике, Паскале или Си) размещают нужные им данные в файлах, организуя их наиболее удобным для себя образом. При этом одни и те же данные могут иметь в разных приложениях совершенно разную организацию (разную последовательность размещения в записи, разные форматы одних и тех же полей и т.п.). Обобществить такие данные чрезвычайно трудно: например, любое изменение структуры записи файла, производимое одним из разработчиков, приводит к необходимости изменения другими разработчиками тех программ, которые используют записи этого файла. Для иллюстрации обратимся к примеру, приведенному в книге: У.Девис, Операционные системы, М., Мир, 1980: "Несколько лет назад почтовое ведомство (из лучших побуждений) пришло к решению, что все адреса должны обязательно включать почтовый индекс. Во многих вычислительных центрах это, казалось бы, незначительное изменение привело к ужасным последствиям. Добавление к адресу нового поля, содержащего шесть символов, означало необходимость внесения изменений в каждую программу, использующую данные этой задачи в соответствии с изменившейся суммарной длиной полей. Тот факт, что какой-то программе для выполнения ее функций не требуется знания почтового индекса, во внимание не принимался: если в некоторой программе содержалось обращение к новой, более длинной записи, то в такую программу вносились изменения, обеспечивающие дополнительное место в памяти. В условиях автоматизированного управления централизованной базой данных все такие изменения связаны с функциями управляющей программы базы данных. Программы, не использующие значения почтового индекса, не нуждаются в модификации - в них, как и прежде, в соответствии с запросами посылаются те же элементы данных. В таких случаях внесенное изменение неощутимо. Модифицировать необходимо только те программы, которые пользуются новым элементом данных.". * Ведение (сопровождение, поддержка) данных – термин объединяющий действия по добавлению, удалению или изменению храни-мых данных. 1.2. Концепция баз данныхАктивная деятельность по отысканию приемлемых способов обобществления непрерывно растущего объема информации привела к созданию в начале 60-х годов специальных программных комплексов, называемых "Системы управления базами данных" (СУБД). Основная особенность СУБД – это наличие процедур для ввода и хранения не только самих данных, но и описаний их структуры. Файлы, снабженные описанием хранимых в них данных и находящиеся под управлением СУБД, стали называть банки данных, а затем "Базы данных" (БД). Пусть, например, требуется хранить расписание движения самолетов (рис. 1.1) и ряд других данных, связанных с организацией работы аэропорта (БД "Аэропорт"). Используя для этого одну из современных "русифицированных" СУБД, можно подготовить следующее описание расписания: СОЗДАТЬ ТАБЛИЦУ Расписание (Номер_рейса Целое Дни_недели Текст (8) Пункт_отправления Текст (24) Время_вылета Время Пункт_назначения Текст (24) Время_прибытия Время Тип_самолета Текст (8) Стоимость_билета Валюта);и ввести его вместе с данными в БД "Аэропорт". Язык запросов СУБД позволяет обращаться за данными как из программ, так и с терминалов (рис. 1.2). Сформировав запрос ВЫБРАТЬ Номер_рейса, Дни_недели, Время_вылета ИЗ ТАБЛИЦЫ Расписание ГДЕ Пункт_отправления = 'Москва' И Пункт_назначения = 'Киев' И Время_вылета > 17;получим расписание "Москва-Киев" на вечернее время, а по запросу ВЫБРАТЬ КОЛИЧЕСТВО(Номер_рейса) ИЗ ТАБЛИЦЫ Расписание ГДЕ Пункт_отправления = 'Москва' И Пункт_назначения = 'Минск';получим количество рейсов "Москва-Минск".
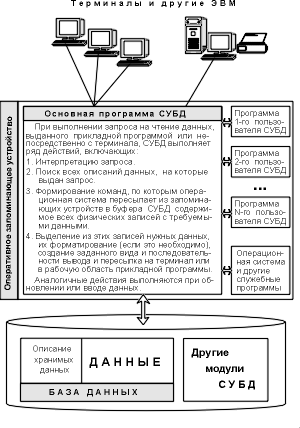
Рис. 1.2. Связь программ и данных при использовании СУБД Эти запросы не потеряют актуальности и при расширении таблицы: ДОБАВИТЬ В ТАБЛИЦУ Расписание Длительность_полета Целое;как это было с программами обработки почтовых адресов при введении почтового индекса (см. п. 1.1). Однако, за все надо расплачиваться: на обмен данными через СУБД требуется большее время, чем на обмен аналогичными данными прямо из файлов, специально созданных для того или иного приложения. 1.3. Архитектура СУБДСУБД должна предоставлять доступ к данным любым пользователям, включая и тех, которые практически не имеют и (или) не хотят иметь представления о:
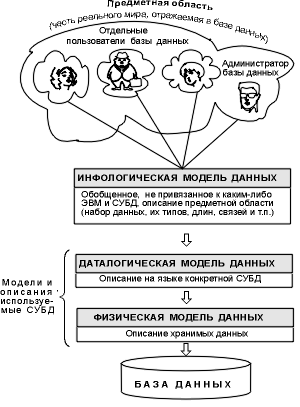
При выполнении основных из этих функций СУБД должна использовать различные описания данных. А как создавать эти описания? Естественно, что проект базы данных надо начинать с анализа предметной области и выявления требований к ней отдельных пользователей (сотрудников организации, для которых создается база данных). Подробнее этот процесс будет рассмотрен ниже, а здесь отметим, что проектирование обычно поручается человеку (группе лиц) – администратору базы данных (АБД). Им может быть как специально выделенный сотрудник организации, так и будущий пользователь базы данных, достаточно хорошо знакомый с машинной обработкой данных. Объединяя частные представления о содержимом базы данных, полученные в результате опроса пользователей, и свои представления о данных, которые могут потребоваться в будущих приложениях, АБД сначала создает обобщенное неформальное описание создаваемой базы данных. Это описание, выполненное с использованием естественного языка, математических формул, таблиц, графиков и других средств, понятных всем людям, работающих над проектированием базы данных, называют инфологической моделью данных (рис. 1.3).
Рис. 1.3. Уровни моделей данных Такая человеко-ориентированная модель полностью независима от физических параметров среды хранения данных. В конце концов этой средой может быть память человека, а не ЭВМ. Поэтому инфологическая модель не должна изменяться до тех пор, пока какие-то изменения в реальном мире не потребуют изменения в ней некоторого определения, чтобы эта модель продолжала отражать предметную область. Остальные модели, показанные на рис. 1.3, являются компьютеро-ориентированными. С их помощью СУБД дает возможность программам и пользователям осуществлять доступ к хранимым данным лишь по их именам, не заботясь о физическом расположении этих данных. Нужные данные отыскиваются СУБД на внешних запоминающих устройствах по физической модели данных. Так как указанный доступ осуществляется с помощью конкретной СУБД, то модели должны быть описаны на языке описания данных этой СУБД. Такое описание, создаваемое АБД по инфологической модели данных, называют даталогической моделью данных. Трехуровневая архитектура (инфологический, даталогический и физический уровни) позволяет обеспечить независимость хранимых данных от использующих их программ. АБД может при необходимости переписать хранимые данные на другие носители информации и (или) реорганизовать их физическую структуру, изменив лишь физическую модель данных. АБД может подключить к системе любое число новых пользователей (новых приложений), дополнив, если надо, даталогическую модель. Указанные изменения физической и даталогической моделей не будут замечены существующими пользователями системы (окажутся "прозрачными" для них), так же как не будут замечены и новые пользователи. Следовательно, независимость данных обеспечивает возможность развития системы баз данных без разрушения существующих приложений. 1.4. Модели данныхКак отмечалось в п. 1.3, инфологическая модель отображает реальный мир в некоторые понятные человеку концепции, полностью независимые от параметров среды хранения данных. Существует множество подходов к построению таких моделей: графовые модели, семантические сети, модель "сущность-связь" и т.д. [11]. Наиболее популярной из них оказалась модель "сущность-связь", которая будет рассмотрена в главе 2. Инфологическая модель должна быть отображена в компьютеро-ориентированную даталогическую модель, "понятную" СУБД. В процессе развития теории и практического использования баз данных, а также средств вычислительной техники создавались СУБД, поддерживающие различные даталогические модели [1, 2, 9, 12]. Сначала стали использовать иерархические даталогические модели. Простота организации, наличие заранее заданных связей между сущностями, сходство с физическими моделями данных позволяли добиваться приемлемой производительности иерархических СУБД на медленных ЭВМ с весьма ограниченными объемами памяти. Но, если данные не имели древовидной структуры, то возникала масса сложностей при построении иерархической модели и желании добиться нужной производительности. Сетевые модели также создавались для мало ресурсных ЭВМ. Это достаточно сложные структуры, состоящие из "наборов" – поименованных двухуровневых деревьев. "Наборы" соединяются с помощью "записей-связок", образуя цепочки и т.д. При разработке сетевых моделей было выдумано множество "маленьких хитростей", позволяющих увеличить производительность СУБД, но существенно усложнивших последние. Прикладной программист должен знать массу терминов, изучить несколько внутренних языков СУБД, детально представлять логическую структуру базы данных для осуществления навигации среди различных экземпляров, наборов, записей и т.п. Один из разработчиков операционной системы UNIX сказал "Сетевая база – это самый верный способ потерять данные". Сложность практического использования иерархических и и сетевых СУБД заставляла искать иные способы представления данных. В конце 60-х годов появились СУБД на основе инвертированных файлов, отличающиеся простотой организации и наличием весьма удобных языков манипулирования данными. Однако такие СУБД обладают рядом ограничений на количество файлов для хранения данных, количество связей между ними, длину записи и количество ее полей. Сегодня наиболее распространены реляционные модели, которые будут подробно рассмотрены в главе 3. Физическая организация данных оказывает основное влияние на эксплуатационные характеристики БД. Разработчики СУБД пытаются создать наиболее производительные физические модели данных, предлагая пользователям тот или иной инструментарий для поднастройки модели под конкретную БД. Разнообразие способов корректировки физических моделей современных промышленных СУБД не позволяет рассмотреть их в этом разделе. |
||||||